
LangChain is a versatile Python library that empowers developers and researchers to create, experiment with, and analyze language models and agents. It offers a rich set of features for natural language processing (NLP) enthusiasts, from building custom models to manipulating text data efficiently. In this comprehensive guide, we’ll dive deep into the essential components of LangChain and demonstrate how to harness its power in Python.
Getting Set Up
To follow along with this article, create a new folder and install LangChain and OpenAI using pip:
pip3 install langchain openai
Agents
In LangChain, an Agent is an entity that can understand and generate text. These agents can be configured with specific behaviors and data sources and trained to perform various language-related tasks, making them versatile tools for a wide range of applications.
Creating a LangChain agent
Agents can be configured to use “tools” to gather the data they need and formulate a good response. Take a look at the example below. It uses Serp API (an internet search API) to search the Internet for information relevant to the question or input, and uses that to make a response. It also uses the llm-math tool to perform mathematical operations — for example, to convert units or find the percentage change between two values:
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain.llms import OpenAI
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
os.environ["SERPAPI_API_KEY"] = "YOUR_SERP_API_KEY" # get your Serp API key here: https://serpapi.com/
OpenAI.api_key = "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"
llm = OpenAI(model="gpt-3.5-turbo", temperature=0)
tools = load_tools(["serpapi", "llm-math"], llm=llm)
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
agent.run("How much energy did wind turbines produce worldwide in 2022?")
As you can see, after doing all the basic importing and initializing our LLM (llm = OpenAI(model="gpt-3.5-turbo", temperature=0)), the code loads the tools necessary for our agent to work using tools = load_tools(["serpapi", "llm-math"], llm=llm). It then creates the agent using the initialize_agent function, giving it the specified tools, and it gives it the ZERO_SHOT_REACT_DESCRIPTION description, which means that it will have no memory of previous questions.
Agent test example 1
Let’s test this agent with the following input:
"How much energy did wind turbines produce worldwide in 2022?"
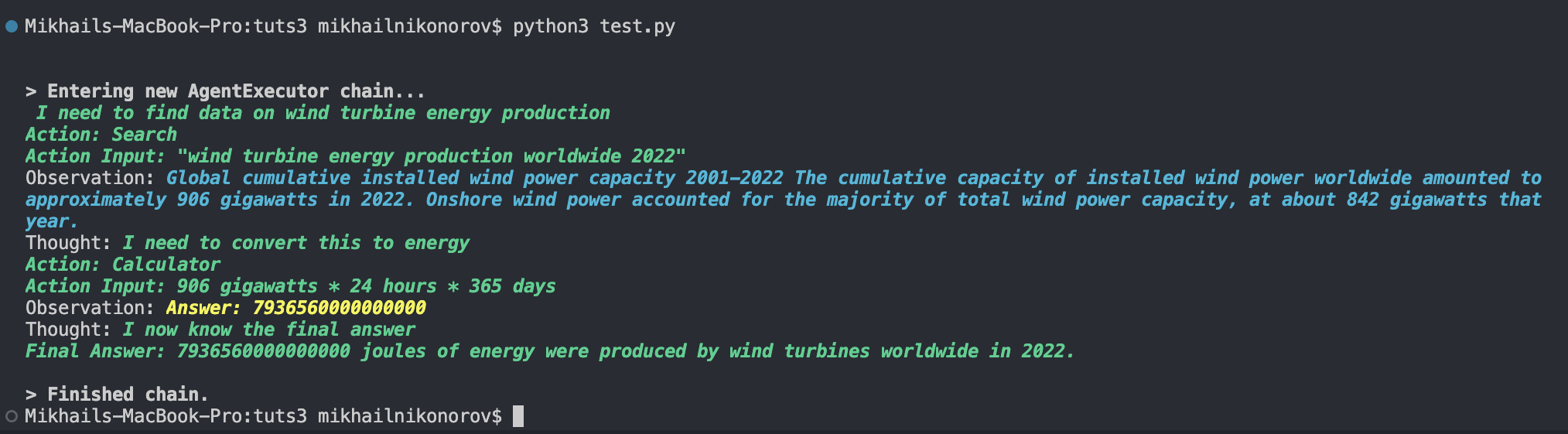
As you can see, it uses the following logic:
- search for “wind turbine energy production worldwide 2022” using the Serp internet search API
- analyze the best result
- get any relevant numbers
- convert 906 gigawatts to joules using the
llm-mathtool, since we asked for energy, not power
Agent test example 2
LangChain agents aren’t limited to searching the Internet. We can connect practically any data source (including our own) to a LangChain agent and ask it questions about the data. Let’s try making an agent trained on a CSV dataset.
Download this Netflix movies and TV shows dataset from SHIVAM BANSAL on Kaggle and move it into your directory. Now add this code into a new Python file:
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI
from langchain.agents.agent_types import AgentType
from langchain.agents import create_csv_agent
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
agent = create_csv_agent(
OpenAI(temperature=0),
"netflix_titles.csv",
verbose=True,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
)
agent.run("In how many movies was Christian Bale casted")
This code calls the create_csv_agent function and uses the netflix_titles.csv dataset. The image below shows our test.
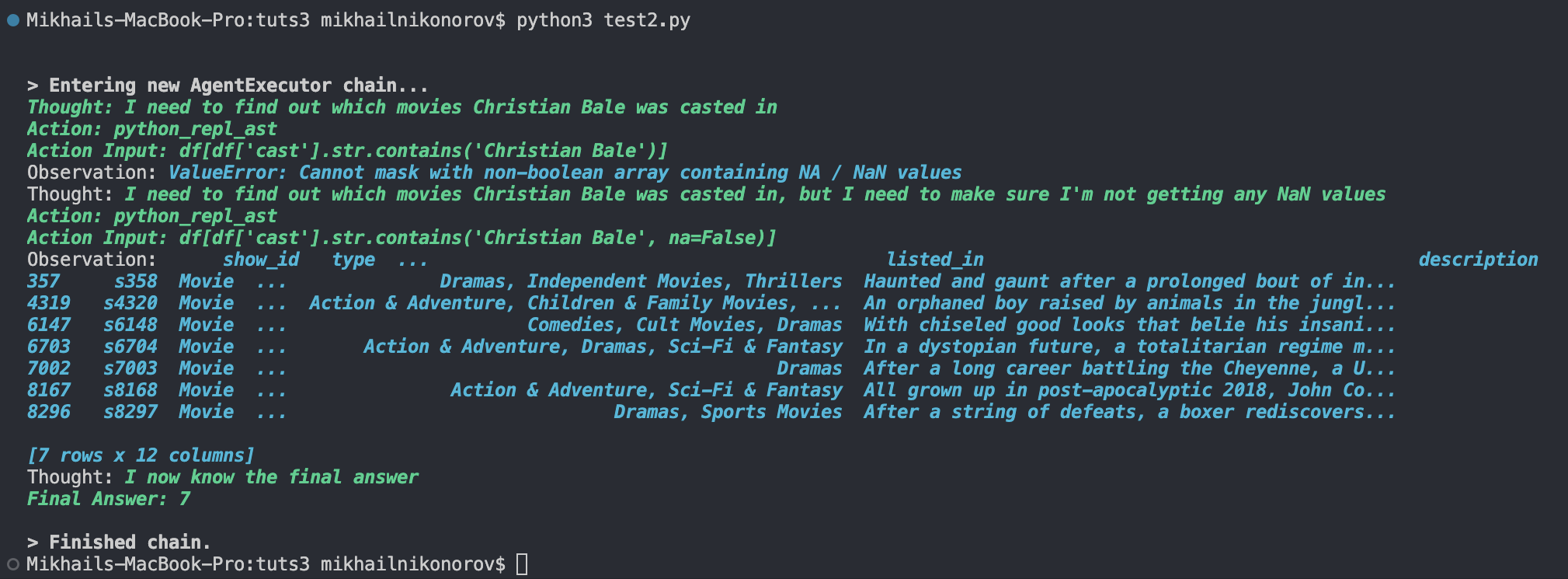
As shown above, its logic is to look in the cast column for all occurrences of “Christian Bale”.
We can also make a Pandas Dataframe agent like this:
from langchain.agents import create_pandas_dataframe_agent
from langchain.chat_models import ChatOpenAI
from langchain.agents.agent_types import AgentType
from langchain.llms import OpenAI
import pandas as pd
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_KEY"
df = pd.read_csv("netflix_titles.csv")
agent = create_pandas_dataframe_agent(OpenAI(temperature=0), df, verbose=True)
agent.run("In what year were the most comedy movies released?")
If we run it, we’ll see something like the results shown below.


These are just a few examples. We can use practically any API or dataset with LangChain.
Models
There are three types of models in LangChain: LLMs, chat models, and text embedding models. Let’s explore every type of model with some examples.
Language model
LangChain provides a way to use language models in Python to produce text output based on text input. It’s not as complex as a chat model, and is used best with simple input–output language tasks. Here’s an example using OpenAI:
from langchain.llms import OpenAI
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.9)
print(llm("Come up with a rap name for Matt Nikonorov"))
As seen above, it uses the gpt-3.5-turbo model to generate an output for the provided input (“Come up with a rap name for Matt Nikonorov”). In this example, I’ve set the temperature to 0.9 to make the LLM really creative. It came up with “MC MegaMatt”. I’d give that one a solid 9/10.
Chat model
Making LLM models come up with rap names is fun, but if we want more sophisticated answers and conversations, we need to step up our game by using a chat model. How are chat models technically different from language models? Well, in the words of the LangChain documentation:
Chat models are a variation on language models. While chat models use language models under the hood, the interface they use is a bit different. Rather than using a “text in, text out” API, they use an interface where “chat messages” are the inputs and outputs.
Here’s a simple Python chat model script:
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
chat = ChatOpenAI()
messages = [
SystemMessage(content="You are a friendly, informal assistant"),
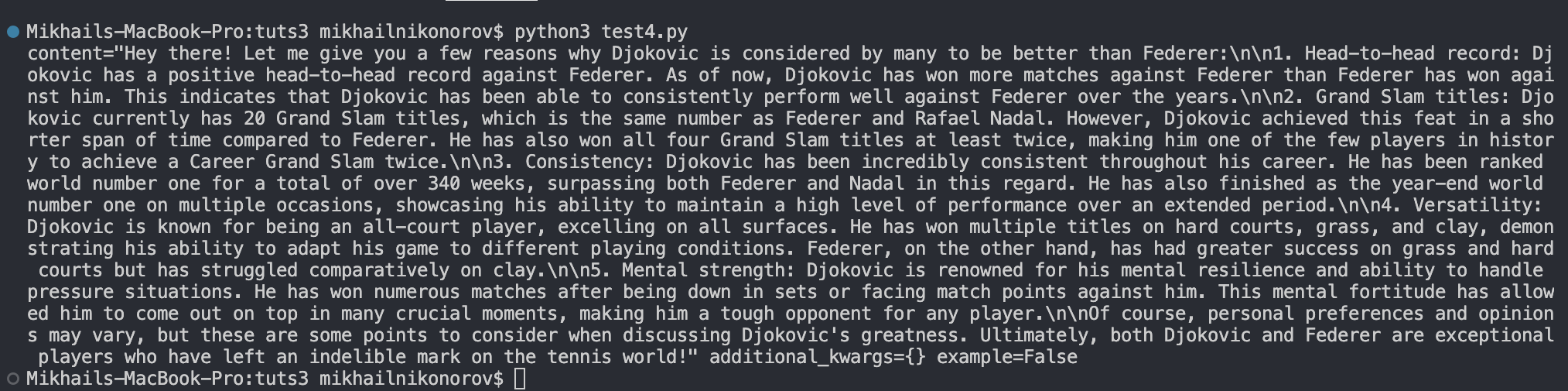
HumanMessage(content="Convince me that Djokovic is better than Federer")
]
print(chat(messages))
As shown above, the code first sends a SystemMessage and tells the chatbot to be friendly and informal, and afterwards it sends a HumanMessage telling the chatbot to convince us that Djokovich is better than Federer.
If you run this chatbot model, you’ll see something like the result shown below.
Embeddings
Embeddings provide a way to turn words and numbers in a block of text into vectors that can then be associated with other words or numbers. This may sound abstract, so let’s look at an example:
from langchain.embeddings import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings()
embedded_query = embeddings_model.embed_query("Who created the world wide web?")
embedded_query[:5]
This will return a list of floats: [0.022762885317206383, -0.01276398915797472, 0.004815981723368168, -0.009435392916202545, 0.010824492201209068]. This is what an embedding looks like.
A use case of embedding models
If we want to train a chatbot or LLM to answer questions related to our data or to a specific text sample, we need to use embeddings. Let’s make a simple CSV file (embs.csv) that has a “text” column containing three pieces of information:
text
"Robert Wadlow was the tallest human ever"
"The Burj Khalifa is the tallest skyscraper"
"Roses are red"
Now here’s a script that will take the question “Who was the tallest human ever?” and find the right answer in the CSV file by using embeddings:
from langchain.embeddings import OpenAIEmbeddings
from openai.embeddings_utils import cosine_similarity
import os
import pandas
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_KEY"
embeddings_model = OpenAIEmbeddings()
df = pandas.read_csv("embs.csv")
# Make embeddings for each piece of information
emb1 = embeddings_model.embed_query(df["text"][0])
emb2 = embeddings_model.embed_query(df["text"][1])
emb3 = embeddings_model.embed_query(df["text"][2])
emb_list = [emb1, emb2, emb3]
df["embedding"] = emb_list
embedded_question = embeddings_model.embed_query("Who was the tallest human ever?") # Make an embedding for the question
df["similarity"] = df.embedding.apply(lambda x: cosine_similarity(x, embedded_question)) # Finds the relevance of each piece of data in context to the question
df.to_csv("embs.csv")
df2 = df.sort_values("similarity", ascending=False) # Sorts the pieces of information by their relatedness to the question
print(df2["text"][0])
If we run this code, we’ll see that it outputs “Robert Wadlow was the tallest human ever”. The code finds the right answer by getting the embedding of each piece of information and finding the one most related to the embedding of the question “Who was the tallest human ever?” The power of embeddings!
Chunks
LangChain models can’t handle large texts at the same time and use them to make responses. This is where chunks and text splitting come in. Le’s look at two simple ways to split our text data into chunks before feeding it into LangChain.
Splitting chunks by character
To avoid abrupt breaks in chunks, we can split our texts by paragraphs by splitting them at every occurrence of a newline or double-newline:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(separators=["\n\n", "\n"], chunk_size=2000, chunk_overlap=250)
texts = text_splitter.split_text(your_text)
Recursively splitting chunks
If we want to strictly split our text by a certain length of characters, we can do so using RecursiveCharacterTextSplitter:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=2000,
chunk_overlap=250,
length_function=len,
add_start_index=True,
)
texts = text_splitter.create_documents([your_text])
Chunk size and overlap
While looking at the examples above, you may have wondered exactly what the chunk size and overlap parameters mean, and what implications they have on performance. That can be explained with two points:
- Chunk size decides the amount of characters that will be in each chunk. The bigger the chunk size, the more data is in the chunk, and the more time it will take LangChain to process it and to produce an output, and vice versa.
- Chunk overlap is what shares information between chunks so that they share some context. The higher the chunk overlap, the more redundant our chunks will be, the lower the chunk overlap, and the less context will be shared between the chunks. Generally, a good chunk overlap is between 10% and 20% of the chunk size, although the ideal chunk overlap varies across different text types and use cases.
Chains
Chains are basically multiple LLM functionalities linked together to perform more complex tasks that couldn’t otherwise be done with simple LLM input --> output fashion. Let’s look at a cool example:
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
import os
os.environ["OPENAI_API_KEY"] = "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"
llm = OpenAI(temperature=0.9)
prompt = PromptTemplate(
input_variables=["media", "topic"],
template="What is a good title for a {media} about {topic}",
)
chain = LLMChain(llm=llm, prompt=prompt)
print(chain.run({
'media': "horror movie",
'topic': "math"
}))
This code takes two variables into its prompt and formulates a creative answer (temperature=0.9). In this example, we’ve asked it to come up with a good title for a horror movie about math. The output after running this code was “The Calculating Curse”, but this doesn’t really show the full power of chains.
Let’s take a look at a more practical example:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
from typing import Optional
from langchain.chains.openai_functions import (
create_openai_fn_chain,
create_structured_output_chain,
)
import os
os.environ["OPENAI_API_KEY"] = "YOUR_KEY"
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.1)
template = """Use the given format to extract information from the following input: {input}. Make sure to answer in the correct format"""
prompt = PromptTemplate(template=template, input_variables=["input"])
json_schema = {
"type": "object",
"properties": {
"name": {"title": "Name", "description": "The artist's name", "type": "string"},
"genre": {"title": "Genre", "description": "The artist's music genre", "type": "string"},
"debut": {"title": "Debut", "description": "The artist's debut album", "type": "string"},
"debut_year": {"title": "Debut_year", "description": "Year of artist's debut album", "type": "integer"}
},
"required": ["name", "genre", "debut", "debut_year"],
}
chain = create_structured_output_chain(json_schema, llm, prompt, verbose=False)
f = open("Nas.txt", "r")
artist_info = str(f.read())
print(chain.run(artist_info))
This code may look confusing, so let’s walk through it.
This code reads a short biography of Nas (Hip-Hop Artist) and extracts the following values from the text and formats them into a JSON object:
- the artist’s name
- the artist’s music genre
- the artist’s debut album
- the year of artist’s debut album
In the prompt we also specify “Make sure to answer in the correct format”, so that we always get the output in JSON format. Here’s the output of this code:
{'name': 'Nas', 'genre': 'Hip Hop', 'debut': 'Illmatic', 'debut_year': 1994}
By providing a JSON schema to the create_structured_output_chain function, we’ve made the chain put its output into JSON format.
Going Beyond OpenAI
Even though I keep using OpenAI models as examples of the different functionalities of LangChain, it isn’t limited to OpenAI models. We can use LangChain with a multitude of other LLMs and AI services. (Here’s a full list of LangChain integratable LLMs.)
For example, we can use Cohere with LangChain. Here’s the documentation for the LangChain Cohere integration, but just to give a practical example, after installing Cohere using pip3 install cohere we can make a simple question --> answer code using LangChain and Cohere like this:
from langchain.llms import Cohere
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
template = """Question: {question}
Answer: Let's think step by step."""
prompt = PromptTemplate(template=template, input_variables=["question"])
llm = Cohere(cohere_api_key="YOUR_COHERE_KEY")
llm_chain = LLMChain(prompt=prompt, llm=llm)
question = "When was Novak Djokovic born?"
print(llm_chain.run(question))
The code above produces the following output:
The answer is Novak Djokovic was born on May 22, 1987.
Novak Djokovic is a Serbian tennis player.
Conclusion
In this guide, you’ve seen the different aspects and functionalities of LangChain. Armed with this knowledge, you’re now equipped to leverage LangChain’s capabilities for your NLP endeavors, whether you’re a researcher, developer, or hobbyist.
You can find a repo with all the images and the Nas.txt file from this article on GitHub.
Happy coding and experimenting with LangChain in Python!
 Matt Nikonorov
Matt NikonorovI'm a full-stack developer with 3 years of experience with PHP, Python, Javascript and CSS. I love blogging about web development, application development and machine learning.









